코딩도 식후경
프로젝트 개요
음식점 리뷰 데이터를 활용한 맛집 추천 및 데이터 시각화 프로젝트
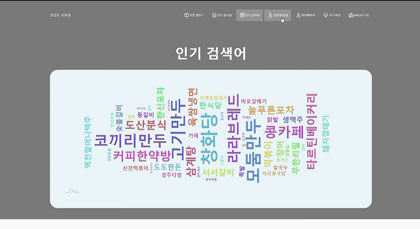
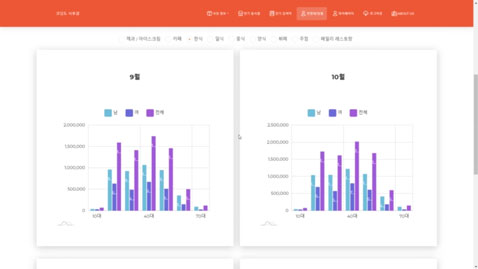
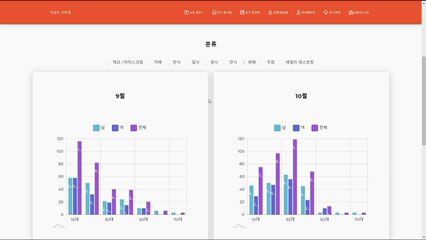
사용자 리뷰에 기반한 추천 알고리즘을 통해 음식점을 추천해주는 서비스입니다. 음식점에 등록된 사용자 리뷰를 확인할 수 있으며, 가장 많이 검색된 음식점이나 메뉴는 워드 클라우드 형태로 시각화하여 제공합니다. 카드사 결제 데이터를 활용하여 음식 카테고리의 성별, 연령별 매출을 그래프로 확인할 수 있습니다.
(단, 카드사 결제 데이터가 2019년 9월~12월로 한정되어 있기 때문에 시각화 기능도 해당 기간으로 제한됨)
프로젝트 개발
- 개발 기간 : 2020. 03. 23 - 2020. 05. 01
- 개발 인원 : 4명
- 역할 : 데이터(음식점 데이터, 카드사 결제 데이터) 전처리, 음식점 추천 기능 구현, 배포
추천 알고리즘 구현 방식
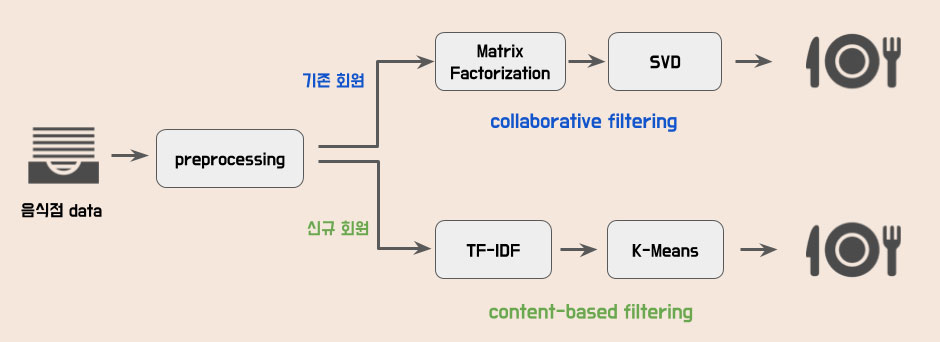
협업 필터링 - 잠재 요인
잠재 요인을 활용한 협업 필터링이란, 사용자-아이템 평점 행렬에 잠재되어 있는 요인이 있다고 가정하고 행렬 분해 기법을 활용하여 그 요인을 찾아내는 방법을 의미합니다.
저는 사용자가 선호하는 음식점 카테고리를 잠재 요인으로 생각하고 만약 어떤 사용자가 중식이나 일식보다 한식을 더 좋아하는 경우, 이 사용자에게 음식점을 추천해줄 때는 한식을 좋아하는 사람들의 특성과 관련이 있어야 합리적일 것이라고 판단하였습니다. 이 과정을 위해 사용자가 음식점에 남긴 리뷰의 평점을 활용하였습니다.
구현은 아래와 같으며 추천을 위해 모든 데이터를 활용하기는 적합하지 않다고 생각했기 때문에 데이터 전처리를 통해 필터링하였습니다.
- 음식점에 등록된 리뷰 개수가 최소 5개 이상은 존재해야 한다.
- 특정 유저가 음식점에 등록한 리뷰 개수가 최소 10개 존재해야 한다.
- surprise 라이브러리가 제공하는
load_from_df함수를 사용합니다. (load_from_df함수에 [사용자id, 음식점id, 평가(score)] 형태로 대응되는 데이터프레임을 전달합니다.)
이 과정이 끝나면 추천을 위한 prediction을 생성할 수 있습니다. 하지만 유저의 요청에 대해 매번 prediction을 로드하거나 업데이트 하기에는 시간이 오래 소요되므로 서버가 처음 실행될 때마다 DB를 조회하여 위 과정을 통해 prediction을 생성합니다.
컨텐츠 기반 필터링
전체 음식점들의 카테고리 키워드에 TF-IDF를 적용하고, 군집화 목적으로 K-Means 알고리즘을 사용하기 위해 sklearn 라이브러리를 활용하였습니다.
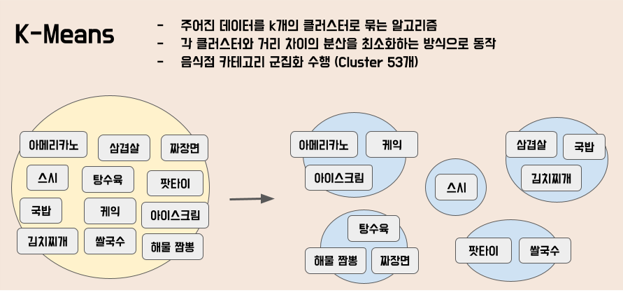

사용자는 회원 가입을 할 때 선호하는 음식점 카테고리를 필수적으로 선택하게 되므로, 사용자가 선택한 음식점 카테고리 정보와 위의 군집화 된 데이터를 활용하여 추천을 해주는 형태로 구현하였습니다.
개발 환경
- 개발 언어 : Python 3.7
- DB : SQLite
- 배포 : AWS EC2, Nginx, uWSGI, GitLab CI/CD, GitLab Runner
- 프레임워크 : Django, Vue.js
- 개발 도구 : Visual Studio Code
- 개발 OS : Windows 10
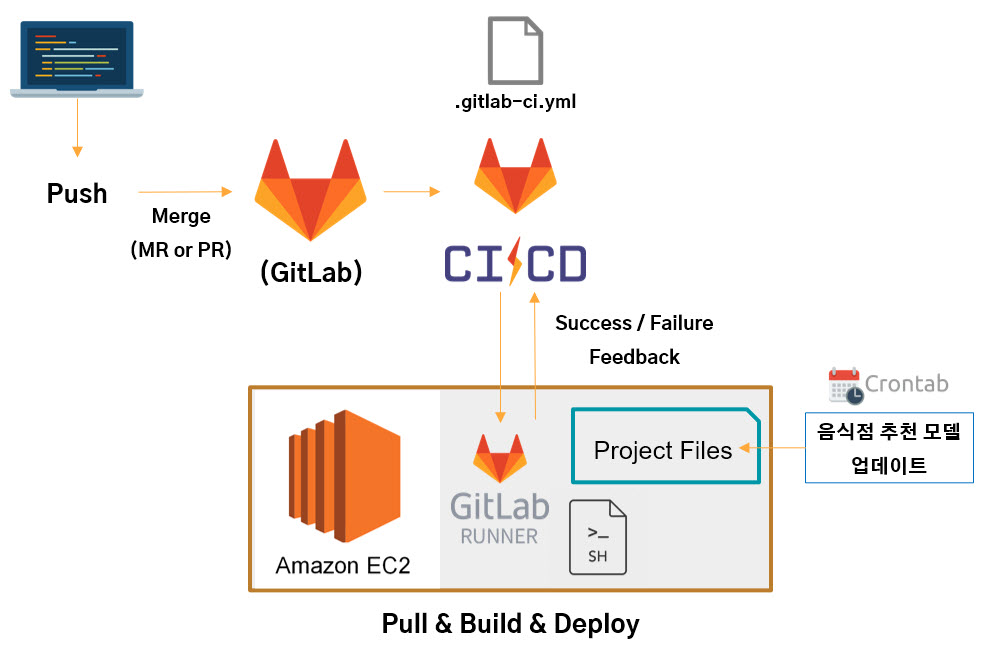
배포 자동화 구조
- master branch에 Merge가 이루어지면 배포가 자동화 되는 구조
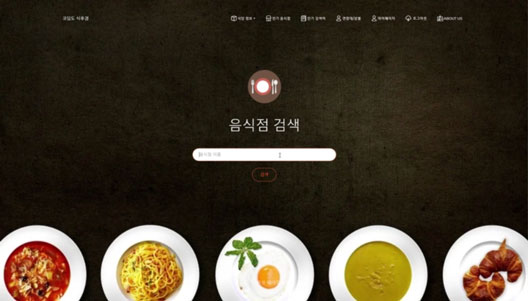
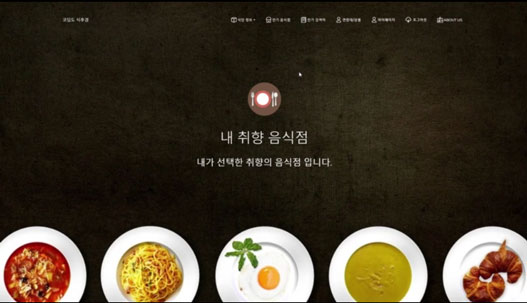
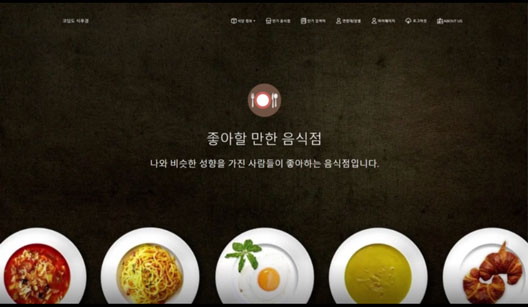
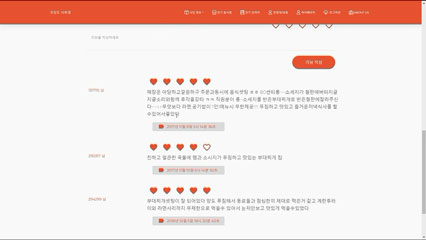
실행 화면
개발 후기
어려웠던 부분
Cold Start 문제
처음 가입한 사용자는 음식점에 등록한 리뷰(데이터)가 없기 때문에 협업 필터링을 통한 추천이 불가하다는 문제(Cold Start)가 있었습니다. 이 문제를 해결하기 위한 방법을 찾아보았고, 기존의 협업 필터링에 컨텐츠 기반 필터링을 결합한 하이브리드 필터링 형태로 구현하여 해결할 수 있다는 것을 알게 되었습니다. 제가 구현한 부분에서는 사용자의 리뷰 데이터가 적거나 없을 때 컨텐츠 기반 필터링을 활용하여 음식점을 추천해줄 수 있을 것이라고 생각하였습니다.
우선 이처럼 개선할 수 있는 사항을 팀에 공유하였고, 회원가입 시 사용자가 선호하는 음식점 카테고리를 직접 선택할 수 있는 페이지가 필요하게 된 부분에 대해 양해를 구했습니다. 기존에 계획되지 않은 작업이었지만 다행히 프론트엔드를 담당하는 팀원이 주도적으로 담당해주었고, 제가 해결해야 할 문제에 집중할 수 있었습니다.
저는 이후에 전체 음식점 카테고리에 대해 TF-IDF를 적용한 후 K-Means 알고리즘을 사용하여 유사한 카테고리별 군집화를 하였고, 사용자가 선호하는 음식점 카테고리 정보를 군집화 된 데이터와 매칭하여 연관된 음식점 중에서 평점이 높은 순서로 추천해주었습니다.
이러한 개선 과정을 통해 Cold Start 문제를 해결하였고 신규 유저와 기존 유저에게 모두 추천을 해줄 수 있었습니다.
협업 필터링 알고리즘 실행 시간
구현한 협업 필터링 알고리즘을 한 번 실행했을 때 추천 결과를 응답 받기까지 17초가 소요되었는데 이것은 사용적인 면에서 긴 시간이었습니다. 추천에 사용되는 행렬 데이터의 크기가 약 100,000x100,000이어서 연산 시간이 오래 소요되는 것으로 생각했지만, 실제로 행렬의 값을 확인했을 때 0값이 많은 희소 행렬 형태로 되어있었습니다. 모든 사용자가 모든 음식점에 대해서 평점을 남기는 것은 아니었기 때문에 발생한 문제라는 것을 알게 되었고, 0값으로 되어있는 부분까지 굳이 연산할 필요는 없었습니다. 그래서 연산 시간을 줄이기 위해 라이브러리(SciPy) 문서를 참고하여 희소 행렬을 압축하였습니다.
추가적으로 추천을 위해 리뷰가 1개만 등록된 음식점 등 모든 데이터를 활용하는 것은 적합하지 않다고 생각하여 음식점에 등록된 리뷰 개수가 최소 5개 이상, 유저가 음식점에 등록한 리뷰가 최소 10개 이상 존재하는 데이터만 추출하는 등 데이터를 필터링하여 음식점 추천에 사용하였습니다.
위 과정을 통해 신규 유저와 기존 유저에게 모두 추천을 해줄 수 있었고, 음식점 추천 결과를 받는 시간을 약 0.5~1초로 줄일 수 있었습니다.
이번 프로젝트를 통해 데이터를 활용하여 사용자에게 어떤 유용한 것을 제공할 수 있는지 생각해보면서, 어떠한 데이터에 기반하여 (사용자에게 추천을 해주는 등의) 인사이트를 도출하고 개발하기 위해서는 해당 도메인 분야에 대한 지식도 필요하다는 점을 배웠습니다.
반복적인 통합과 배포의 자동화는 팀의 생산성을 높여주었고 서비스도 신속하게 배포할 수 있었습니다. 그리고 크론탭을 사용하여 새벽마다 서버를 재시작하면서 음식점 추천 모델의 업데이트와 서빙을 했는데, 현재 구조에서는 추천 모델을 업데이트 하는 동안 서비스를 이용할 수 없기 때문에 새로 누적되는 데이터를 활용하기 위한 좀 더 체계화 된 파이프라인의 필요성을 느꼈습니다.
코로나19로 인하여 비대면 상황에서 처음 진행하는 프로젝트이다 보니 개발 중에는 서로 어느 작업을 하고 있는지 직접적으로 파악하기 어려울 것이라는 걱정도 됐는데, 오전 데일리 스크럼을 진행한 이후에도 일과시간에는 항상 화상 미팅을 켜두고 있었기 때문에 궁금한 점이 있으면 바로 피드백을 얻을 수 있었고 코드를 함께 봐야할 때 화면 공유 기능을 활용하면서 잘 마무리할 수 있었습니다.
팀원들과 협업하며 프로젝트를 완수하였고, 프로젝트 본선 발표회에서 우수상을 수상하였습니다.